In this case study, we outline our work with Superlayer, a modern revenue platform for B2B sales teams, to design and develop the Conversation Intelligence module. The module enables Superlayer's customers to optimize their sales processes, better understand clients, and gain valuable insights from their business conversations.
Superlayer sought to enhance their platform by incorporating a Conversation Intelligence module. They aimed to provide sales teams with a tool to record, analyze, and extract valuable information from sales calls, ultimately helping them understand their customers better and improve sales efficiency.
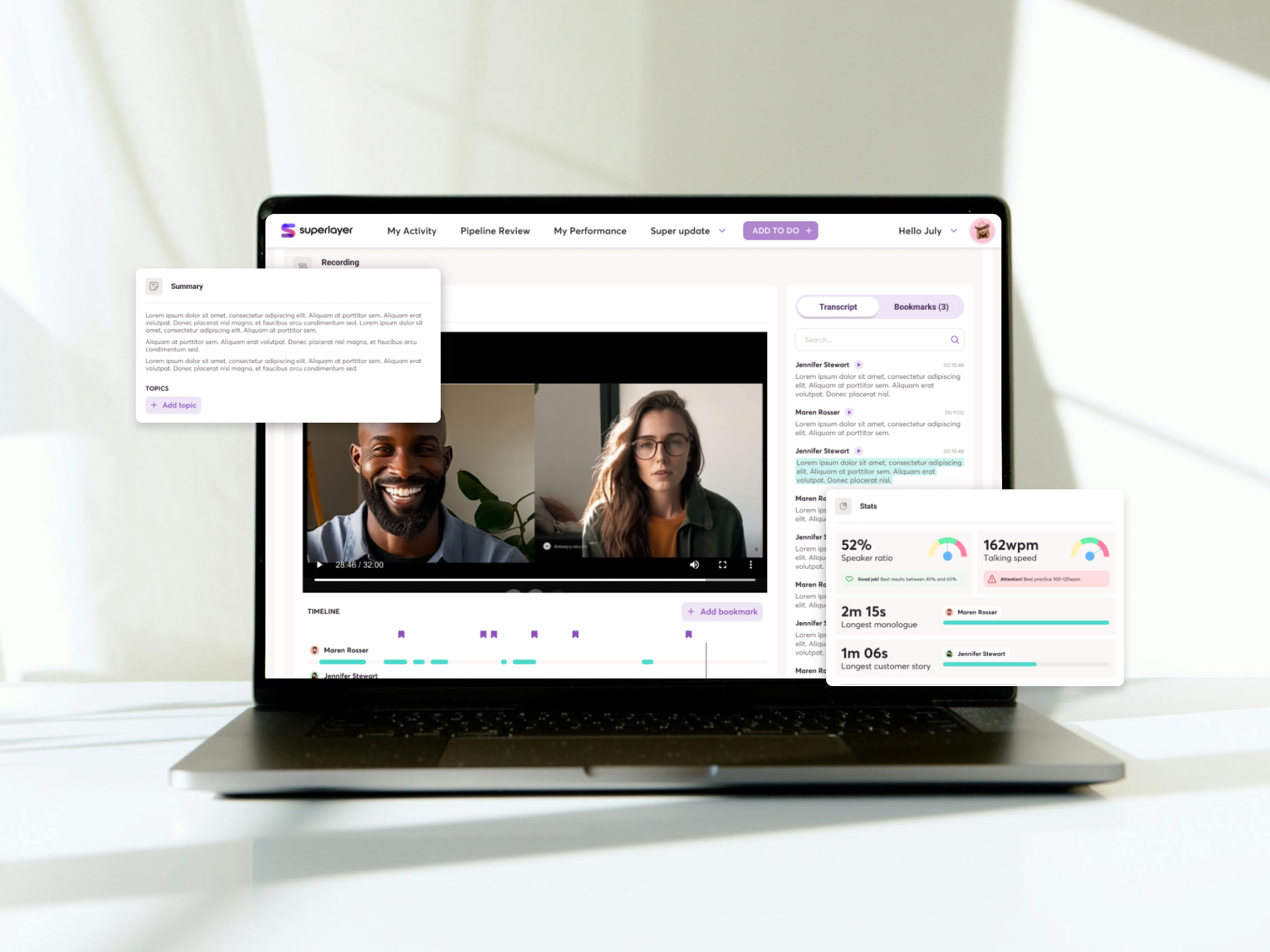
Leveraging recent AI advancements in natural language processing (NLP) and speech recognition, the Conversation Intelligence module aims to efficiently analyze and extract valuable information from sales calls. By employing accurate speech-to-text transcription and cutting-edge AI models and presenting the results in an intuitive user interface, the new module allows for faster ramp-up times for new members of the team as well as increased efficiency for senior reps.

Superlayer’s team collaborated with Buildo to design and develop the conversation intelligence module, seamlessly integrating it into the existing platform. The module records sales calls, generates transcripts and summaries, and provides insights that enable users to gather valuable information and analysis from the calls. This allows Superlayer's customers to quickly evaluate the status of a deal and optimize their sales processes without re-watching entire calls or taking notes during the meeting.
By tagging calls, sales representatives can swiftly filter and locate similar calls within their team, analyzing outcomes and strategies employed. Furthermore, sales team managers gain access to a wealth of statistics, empowering them to monitor individual performance, pinpoint areas for growth, and provide targeted mentoring to elevate their team's success.
In order to develop an effective Conversation Intelligence module for Superlayer, our team conducted a thorough analysis of the available technical solutions. We sought to identify the best combination of technologies that would enable seamless meeting recording, accurate transcription, and insightful analytics, all while being user-friendly and reliable.

We assessed various AI models to perform speech-to-text. While many models excelled in English language processing, we found that their performance diminished for other languages. Upon obtaining the transcripts, we aimed to explore diverse approaches for generating valuable summaries, identifying crucial topics, and extracting key insights from each call.
When a sales representative joins a scheduled call with a client, the entire session is recorded. In an asynchronous fashion, the call is permanently stored and a transcript is generated. Once the raw transcript is ready, a customized data transformation is performed to provide advanced features such as the timeline and the diarized text. Intermediate results of the overall process will be available as soon as its corresponding sub-task is completed for a promptly and seamlessly user experience.

The feature’s primary focus is to extract valuable observations that indicate whether a client has a solid inclination to purchase or try out a product or if there is any indication to the contrary.
To accomplish this, we employed specific Prompt Engineering strategies, including:
Given that the LLM's input and output do not fit within the maximum model tokens available, a token window (segmenting) approach was involved. Even if it does come with the drawback of making more API calls, we found out that this strategy best meets the feature requirements.
Our collaboration with Superlayer resulted in a powerful Conversation Intelligence module that empowers sales teams to better understand their customers and optimize their sales processes. The feature assists Superlayer’s customers in reducing the time spent reviewing sales calls and helps them achieve increased efficiency with faster ramp-up times and higher win rates.

Are you searching for a reliable partner to develop your tailor-made software solution? We'd love to chat with you and learn more about your project.



