

Unprecedented breakthroughs in LLMs are transforming software development. New techniques enable effective interactions with LLMs, but caution is advised to avoid unnecessary complexity. Buildo embraces these advancements to enhance products and refine quality in Software Engineering.
In the annals of technological advancements, Feb-Mar 2023 undoubtedly marks a milestone of noteworthy significance in the spheres of Artificial Intelligence and Software Engineering. The month saw unprecedented breakthroughs in generative AI, including the introduction of cutting-edge Large Language Models (LLMs) such as Openai’s GPT-4 and Meta’s LLaMA. These LLMs stand at the forefront of emerging tech, aiming to revolutionize several aspects of web software development, from optimizing internal workflows to developing product features previously unattainable due to financial or complexity constraints.
The new wave of LLM technologies has opened the doors to unparalleled opportunities, considerably elevating our software solutions' speed, efficiency, and sophistication.
At Buildo, we view the advent of LLMs not just as another leap in technology but as a strategic tool for evolving our software development company in two directions:
The following article focuses on how we are tackling the first goal.
The LLMs advent created a demand to incorporate their capabilities into conventional software, rather than only using them as end-user tools. Thus, emerging architectures around LLMs were born: just like any other technology, they come with design patterns, guidelines, and best practices.
They provide a framework to interact with LLMs by decomposing and isolating responsibilities. The fundamental concept, named In-context learning, aims to control an off-the-shell LLM through advanced prompting, custom use-case data, and business logic.
The base interaction with a generic LLM consists of a finite list of messages (chat) between the user and the agent, including contextual information. Unfortunately, the overall chat is limited due to the technical model tokens cap, thus, a large amount of data cannot be provided as contextual information.
The In-context approach solves this problem by providing only contextual information that should be sufficient for a specific user query given a large amount of source data. The around architecture is essential to determine which information among all should be injected.
The power of this paradigm, as opposed to fine-tuning or distillation techniques, relies on no AI expertise or high training costs. Additionally, models are now provided as a service, completely obviating the management and deployment effort.

Conceptually, the In-context approach can be divided into three stages:
Data preprocessing consists of chunking, embedding, and storing private data to be used for contextual information. Heterogeneous sources such as text documents, PDF, and even structured data (SQL, JSON) can be used. Each source content is chunked and described by certain metadata. The embedding step involves passing the content through an LLM embedding model, which outputs a numerical representation (vector) of the content. Finally, the embeddings are stored in a specialized database (ie. vector database) that provides efficient primitives for comparison and navigation.
Prompting Engineering is becoming tailored and advanced: complex techniques, such as Chain-of-Thought, Automatic Reasoning, or Self Consistency, can be used to direct the reasoning of the language model. Prompt construction is the stage that automates these techniques and data templating from the previous step. In this step, agents can also apply custom business logic to alter or integrate prompt construction from the external world (eg. contacting a web API). Moreover, in a matryoshka fashion, these agents could be LLMs themselves, thus autonomously deciding how to alter the prompt in a fine-tailored way.
Finally, the constructed prompt is executed, and the output from the core LLM is used to build up the final steps of our LLM-based applications. Typically, post-processing is applied to structure the outputted data and perform validation.
Implementing such architecture is not naive. Fortunately, there are frameworks that orchestrate all the stages and provide a ready-to-use implementation for data loading, data storage, and LLM interaction. The most notorious ones, that we decided to use in Buildo, are LlamaIndex and LangChain: they provide easy-to-use APIs enabling developers to build up all the described stages in just a few lines of code.
load_dotenv('./.env')
openai.api_key = os.getenv("OPENAI_API_KEY")
# Data Preprocessing
reader = SimpleDirectoryReader(input_dir=SOURCE_DIR_PATH)
documents = reader.load_data()
index= VectorStoreIndex-from_documents(documents)
# Prompt Construction
# ...
# Prompt Execution
query_engine = index.as_query_engine()
response = query_engine.query(sys.argv[1])
print(response)In-context learning is not mutually exclusive to fine-tuning. It is possible to fit in any LLM, from the proprietary to the open source ones, fine-tuned or not. The point of fine-tuning is to specialize a model for a business use case. It can be extremely effective, but it requires Machine Learning expertise and high cost for model training and management.
AI companies are providing fine-tuning as-a-Service which dramatically downsizes these costs. On the other hand, AI expertise only comes from human resources that might not be already present in the company. In Buildo, for example, we have a base foundation in Machine Learning, but, with the fastening advance of AI, we are constantly enhancing our internal learning effort to develop a skillset for AI engineering.
We saw how basic Software Engineering helped create a framework around LLMs to be easily integrated into applications. So, where is the risk?
As per any new technology: overdoing. When something new comes in, we engineers are prone (with some pressure from the market) to include the latest thing in any new solution we are making. Additionally, having these emerging architectures make it really easy to integrate LLMs on a broad level.
The point is LLM technology addresses specific problems that anything else cannot. In contrast, heuristic solutions still work and are generally more efficient and cheaper.
Given a complex problem to solve, it is extremely important first to tackle it via divide and conquer. Identifying the minimum addressable sub-problems gives you more perspective on how to solve them. With high probability, most of the sub-problems can be easily solved by heuristics. AI should be used where it is more effective or necessary. Even if you think a problem can be solved entirely by an LLM, pre and post-processing are the typical hard-to-identify sub-problems that can be solved via heuristics, occasionally in a more robust and efficient way.
Thanks to the frameworks discussed and the general availability of LLM-as-a-Service, using a plug-in strategy and making sub-problems solutions interacting each with another is now pretty straightforward. In this way, the overall solution balances costs and provides value, mitigating the risk of using excessive technologies for simpler issues.
In Buildo, we are at the front line to experiment and evolve our services by integrating AI solutions. We had the chance to collaborate with Superlayer.co, a ramping startup in the sales pipeline business.
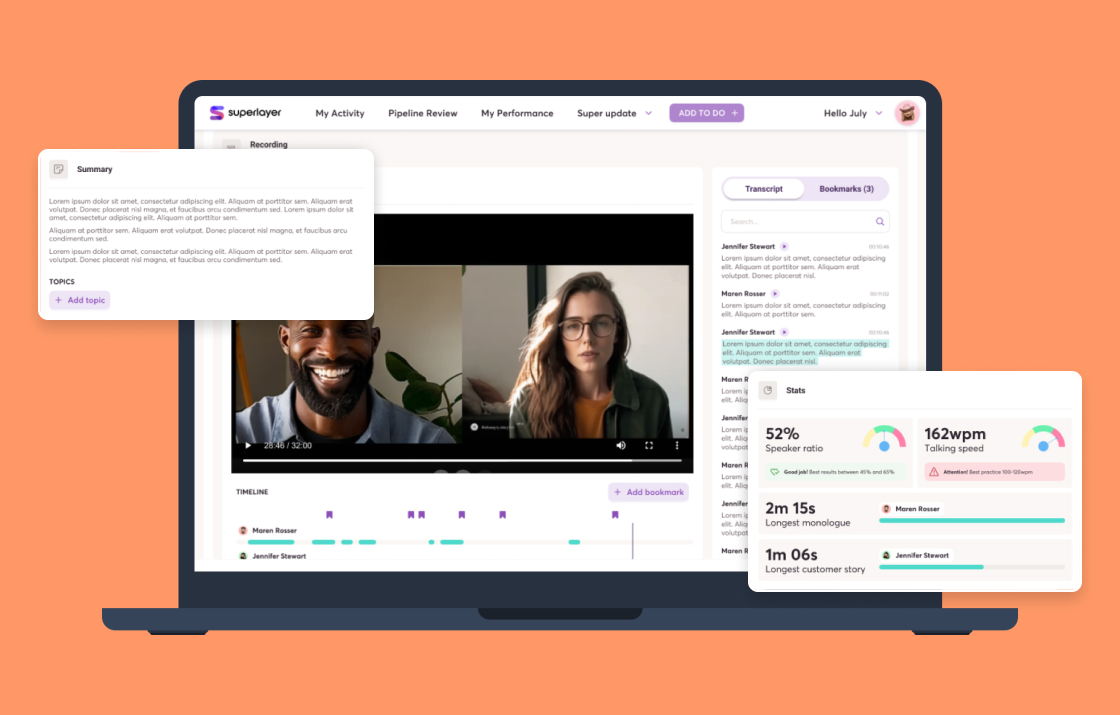
We synergically developed a Conversational Intelligence feature within the Superlayer’s platform able to:
For the intelligence insights, we leveraged LLM technology with the most common Prompt Engineering techniques to provide robust and valuable information to the sales representatives based on the calls context.
Take a look at the detailed case study here and to the best software development tools on Design Rush.
To sum up, the emerging architectures around LLMs equip software technologies with unprecedented transformative power. Software Development Companies like Buildo can leverage the “In-context learning” approach to develop AI features with no advanced LLMs expertise and costly training.
Yet, one must remain prudent to avoid the risk of overdoing. Dividing complex problems, utilizing heuristics, and applying AI only where most valuable ensure a cost-efficiency trade-off.
At Buildo, we are dedicated to leveraging these advancements not just to enhance our products with previously unattainable functionalities, but also to focus more on refining quality-related aspects of software engineering.
Matteo is a product-oriented Software Engineer. He cares about business impact and UX/UI while keenly nerding on the software architecture. He enjoys bootstrapping and scaling up digital products. He passionately dedicates himself to integrating AI into software engineering.
Are you searching for a reliable partner to develop your tailor-made software solution? We'd love to chat with you and learn more about your project.




